
【講演原稿】AIとは何か?ビジネスはどこへ行くのか?
大阪産業大学
2025年11月24日、大阪産業大学の『ITビジネス企画論』にて、弊社スタッフが登壇しました。本記事ではCTO山内の講演パート「AIとは何か?ビジネスはどこへ行くのか?」を全文書き起こしで公開します。
はじめに
こんにちは。株式会社 itomaAI 代表、兼、CTO の山内です。CEO の橋本に続きまして、私の方からは AI の中身の話と、AI とビジネスの話をさせていただければと思います。
まず簡単に自己紹介させてください。私は大学では哲学をやっていました。ちょっとした縁から2015年に株式会社ALBERTというデータ分析会社でバイトをはじめ、2017年大学卒業とともにそのまま入社。深層学習の案件に6年ほど携わった後に、東京大学 松尾・岩澤研究室に移り、1年ちょっと基礎研究やったあとで、今年1月に itomaAI を起業しました。
起業したばかりなので、経営者としてはまだまだ若輩者で、正直な話ここでお話する資格が自分にあるのか悩ましいところなのですが、とはいえ、私が AI を用いた仕事に関わり始めて10年たったことですし、第三次AIブームのまっただ中にいた技術者として、またAIをテーマに起業した経営者として、個人的な経験をお話させていただければと思います。あくまで の意見として聞いてください。
AIについて
AIとは何か
さて、AI とはなんでしょうか?最近話題の生成AI、言語モデル、これは AI ですね。将棋や囲碁をプレイするAIもいます。AI とは何かについては面白い冗談があって、「普及したAI技術はAIとは呼ばれなくなる」というものです。AI というのは Artificial Intelligence つまり人工的に知的な操作をする何かを指すわけですから、計算機とか検索エンジンとかだってある意味では人工知能ですし、人が乗った駅と降りた駅から乗車料金を計算するシステムなんかもAIですね。でも現在それをAIと呼ぶ人はあまりいません。あまりに当たり前になってしまった技術は、あえてAIとは呼ばないわけです。そういう事情があるので、AI研究者はあまり自分をAI研究者とはいいません。深層学習の研究者だとか、数理統計の研究者だとか、自然言語処理の研究者だとか、そういう自己紹介をする人が多いです。AIって流動的な概念ですし、誇大広告っぽい時代が続いていたので。
でも最近、流石にこれは AI と呼んでいいし、これからも呼ばれ続けるだろう、というレベルの AI が登場してきました。彼らは私含めておおかたの人間より流暢に言葉を操りますし、いろんな課題を汎用的に解くことが出来ます。それらを「知的」だと呼ばないのであれば、我々人間だって知的生命体だと呼ぶのは難しいかもしれない、くらいのところに来つつある。自分は大変面白い時代に生まれたものだと思うわけです。
ちょっと話が脇道にそれました。で、AI とは何かという話。極端に抽象化して言うなら、AI というのは関数です。中学高校とやってきたと思いますが とかいうあれです。関数は、 に を対応付けます。つまり が決まれば が決まります。 が なら は ですね。
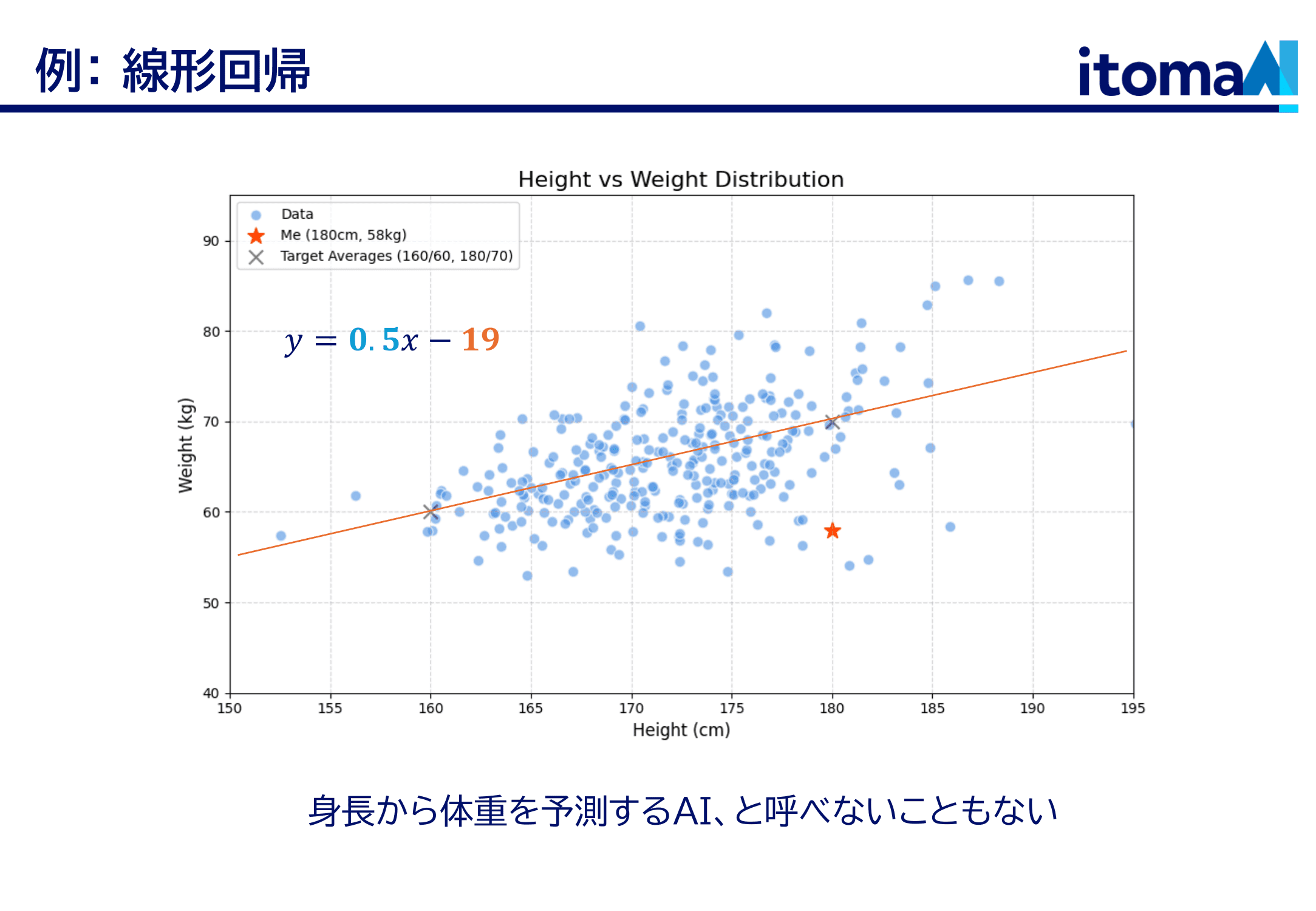
ここに身長と体重の散布図があります。一つ一つの点が一人の人間ですね。この人(★)は身長180cmで体重58kgです。ちょっと痩せていますね、私なんですけれども。さて、ここに一本の直線があります。統計の言葉で言うと「回帰直線」というわけですが、これは言ってしまえば「身長から体重を予測する」関数です。直線なので一次関数ですね。式で言うと くらいになります。で、このxに値を代入すると体重がわかる。だいたい身長180cmの人は体重70kg。ちょっと外していますが、まあ概ねあたっている。誤解を恐れずに言えば、これは身長から体重を予測するAI、ということになる。誰もAIとは呼びませんが。
そして、AI、そのベースとなっている機械学習という技術は、「データ(この場合は散布図の点)から関数を逆算する」技術です。 の のところ、これらの数値はパラメータと呼んだりしますが、これを決めてやるのが、要するに「学習」です。そして学習で決めた を使って を求めるのが「推論」とか「予測」になります。

これと ChatGPT、ほんとに同じものなのかと思うかもしれません。ここで考えてほしいのですが、言葉とか画像とかいったものも、やろうと思えば数値で表せるわけです。文字なら , , , ... とやればいいし、画像だって細かい四角(ピクセル)に分割して、それぞれの色を RGB で指定してやれば良い。どういう仕方で表現するかは任意性がありますが、とにかく可能なわけです。すると、例えば「これはなんですか」を数値化した に、応答「ペンです」を数値化した を返す関数が存在するなら、会話は関数によって行えるわけです。画像認識なんかも同じですね。
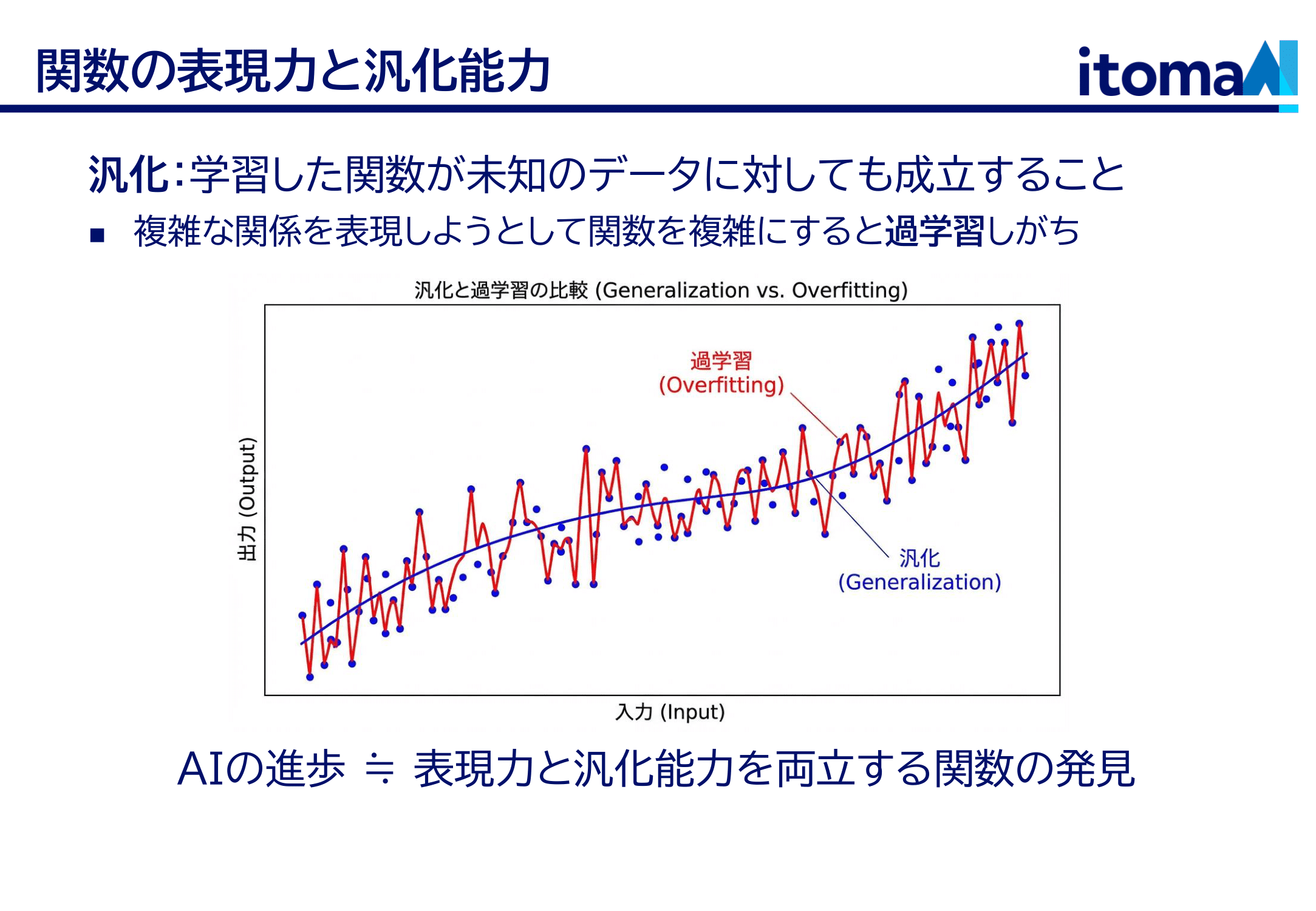
さて、さっきの身長体重の話にちょっと戻ります。この例では、身長と体重の関係を直線で表しました。直線でモデル化する、線形モデルとか言ったりしますね。でも本当に直線で良かったのでしょうか?実際のところ、その関係は直線的ではありません。よく見ればわかるように、身長が大きくなると体重は線形よりも早く増えていっています。つまり一次関数という関数では表現できないわけですね。じゃあもっと複雑な、二次関数とか三次関数とか、パラメータが大きくてとにかくどんな関係でも表現できる関数を使えばよいのでしょうか?実はそれにも問題があります。データというものは有限なので、パラメータを決定できなくなるのです。 例えば下の図を見てください。この曲線はデータ点のところをきれいに通っています。でも、データのないところの挙動がめちゃくちゃで、実際の予測には全然使えないのです。機械学習にはつねにこの問題がついて回ります。与えられたデータを表現する関数は実のところ無数にある中で、与えられなかったデータに対しても妥当な振る舞いをする関数を見つけられるか?ということです。未知のデータの関係をもちゃんと捉えられていることを「汎化」といいますが、AIの進歩の技術的側面とは、いかに表現力と汎化能力を両立する関数を発見するか、という点にあったと言えます。
AI発展史

ちょっと歴史の話をしましょう。AIの歴史は案外古く、電子計算機が誕生した頃にはすでに研究者たちは人工的な知性の可能性を考えていました。最初の頃は論理的な推論を積み上げることによって知的な機械を作ろうとしていたようです。論理というのは、三段論法みたいなやつですね。それを大量に組み合わせて、人間のような判断を実現しようとした。計算機というのはそもそも論理学から出てきたようなところがあるので、まあ自然な流れです。ただこれはあまりうまくいかない。この世界って別に論理的ではないわけですね。「こんにちは」に対して「こんにちは」と返すか「この野郎」と返すかは様々な文脈や条件によって決まるわけで、論理式に変形できるわけではない。人間が頭をひねって抽象化して論理的骨格を取り出して初めて、論理演算とかが有効になるわけです。そのレベルではたしかに計算機は有効です。ITシステムってそうやって作られますね。世の中の仕組みを頑張って整理して、プログラムで書けるくらい単純化して、そうしてようやくシステムとして実装できる。その泥臭い部分にこそ知性の努力があったわけです。
この論理で頑張ろうとしたのが第一次AIブームと呼ばれる時代で、それからしばらくして第二次がやってきます。1980年あたりからですかね。あまり私は詳しくないですが、エキスパートシステムという言葉がもてはやされた頃です。人間の専門知識をルールベースで機械化しようという試みでしたが、これもそんなにうまくいっていません。現実が複雑過ぎてルールに落とし込めないのです。
またこの頃、現在のAIの基本的な仕組みであるニューラルネットワークも登場してきています。ニューラルネットワークを誤差逆伝播法で訓練するという枠組みや、深層学習の立役者であった畳み込みニューラルネットワーク(CNN)のアイディアが出てきた時代です。CNN のアイディアを出したのは福島先生という日本の研究者ですし(今につながる源流は LeCun かもですが)、誤差逆伝播法を甘利先生が独立に発明していたり、日本の存在感も結構あった時代です。
そこからしばらく冬の時代がやってきます。基本的なアイディアは出揃っていたのに、どうしてニューラルネットワーク冬の時代に突入したのか。いろいろ理由はあるんでしょうが、計算機の性能が足りなかったのと、学習データが整備されていなかったのが大きいんじゃないでしょうか。アイディアはあっても、それを実現する基盤が社会になかった。そこからしばらくは理論的研究のほうが盛んになります、ボルツマンマシンとかね、個人的にはかなり面白いと思うんですが。
そして第3次 AI ブーム。きっかけは ILSVRC という画像認識コンペで、画像に何が写っているかを機械的に判別するっていう勝負をいろんな研究者がやってたんですが、それまで毎年数%ずつ精度を上げていってたところで、ニューラルネットベースのモデルが一気に10%くらい精度更新するんですね。何だこれはとみんな驚いたところで、聞いてみると中身はニューラルネットだという。作ったのはヒントン先生という人で、冬の時代を耐えきった研究者です。さっきちらっといったボルツマンマシンとかもこの人ですね。ニューラルネットで行けるはず、という信念を持ってずっと頑張ってて、それにようやく時代というか技術が追いついた。研究の世界だとこういうことがよくあります。頭いい人はさっと流行りの分野に移っちゃうんですけど、メチャクチャな成果を上げるのってこの種の頑固者なわけです。
で、ニューラルネットでまだまだ行けそうだぞってことで、それが今まで続いています。私がAIやり始めのもこの頃ですね。みんな使っている ChatGPT の中身もニューラルネットワークです。ニューラルネットワークって説明なしにこれまで言ってましたが、これもある種の関数です。もちろん、一言にニューラルネットと言っても色んな形があり、MLP やら CNN やらあって、その中で表現力と汎化能力の高いものをみんなで探してます。最近の ChatGPT みたいな言語モデルは Transformer というニューラルネットワークを使っています。これが出てきたのは 2017 年で、グーグルの研究者が確か機械翻訳の文脈で出してきたやつだった気がします。Transformer の能力については後で話しますね。
AIの進歩を牽引してきたもの
先程も触れましたが、AI の発展には3つの要素があったと思っています。
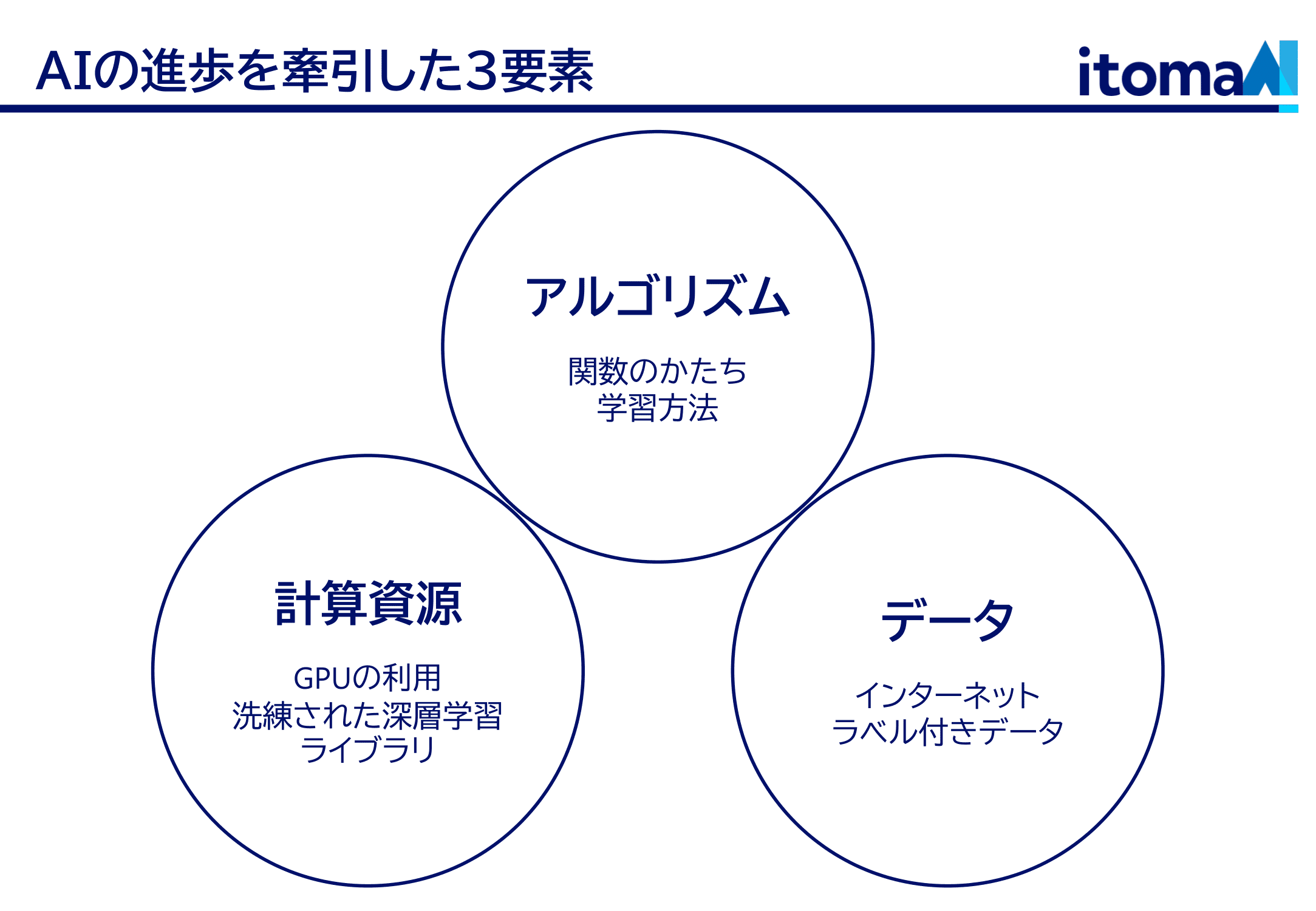
ひとつは、どういう関数を使うか、どうやって学習させるかという、AIの原理的な部分。今もみんな熱心にやってます。
もう一つは計算機の能力。ニューラルネットワークには何億ものパラメータ(一次関数の の部分)があります。ChatGPTとかになると兆の桁ですね。これを計算するには、とんでもない計算リソースが必要です。余談になりますが、ニューラルネットワークの計算に使われている計算チップは、元は3Dゲームの画面を描画するために作られたものでした。ゲームの画面描画もニューラルネットの計算も、結局は行列の掛け算で、やっていることは一緒なのです。それから、計算のためには凄まじい電力も必要です。こういう計算インフラがあって初めて、理論を現実にうつすことが出来ます。
そして、学習データ。AIそれ自体はただのめっぽう複雑な関数であって、そのパラメータを調整して初めて意味のある結果を出します。その調整のためには大量のデータが必要です。第3次AIブームは画像認識コンペから始まったといいましたが、このコンペを開催している人たちも偉かったわけです。何百万枚ものラベル付きの画像データを手で作って提供してたわけですから。
大規模言語モデルとその未来
さて話を AI の中でも大規模言語モデル、LLMと呼ばれるものに移しましょう。みなさんも使ったことあるんじゃないかと思います。使いこなしてるよって方もいるかもしれません。
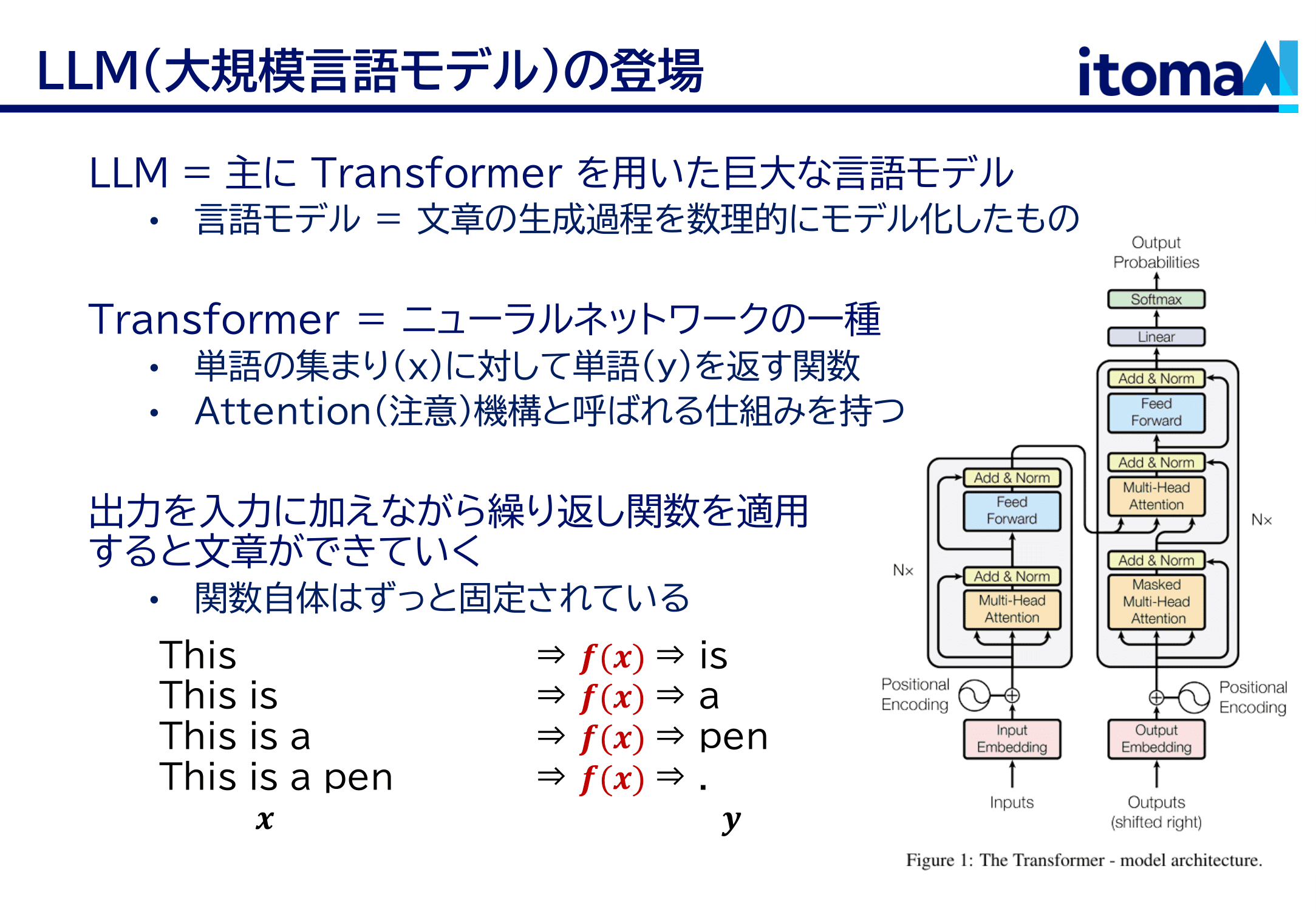
LLM の基礎は先程少し触れた Transformer という関数です。これは「attention, 注意機構」と呼ばれるものを持っています。面白い性質を持っているのですが、結局はこれも関数で、単語の集まり(を数値化したもの)を として受け取って、ひとつの(ひとつに限らないけども)単語(を数値化したもの)を y として返します。これを使うと、this → is, this is → a, this is a → pen という感じでくるくる回していくことで文章を書かせられるんですね。こういうやり方を auto-regressive なテキスト生成とか言ったりしますが、ChatGPT はこんなやり方で文章を出力しています。
注意してほしいのは、LLM は文章に次の単語を付け足す関数をくるくる回しているというだけで、この関数自体はずっと固定だってことです。LLM を構成する関数自体は、ユーザーとの会話の中で何かを記憶したりとかはしません。ただ書かれたものに続きを書き加えるという作業をやっているだけです。LLM が文脈に沿った会話ができるのは、単にこれまでの会話の中に文脈が書き込まれているからです。例えるなら、一単語書き加えるごとに、記憶を全部失って、今までの文章を読んで思い出して、一単語書き加えて、またすべて忘れる、ということを繰り返している感じでしょうか。
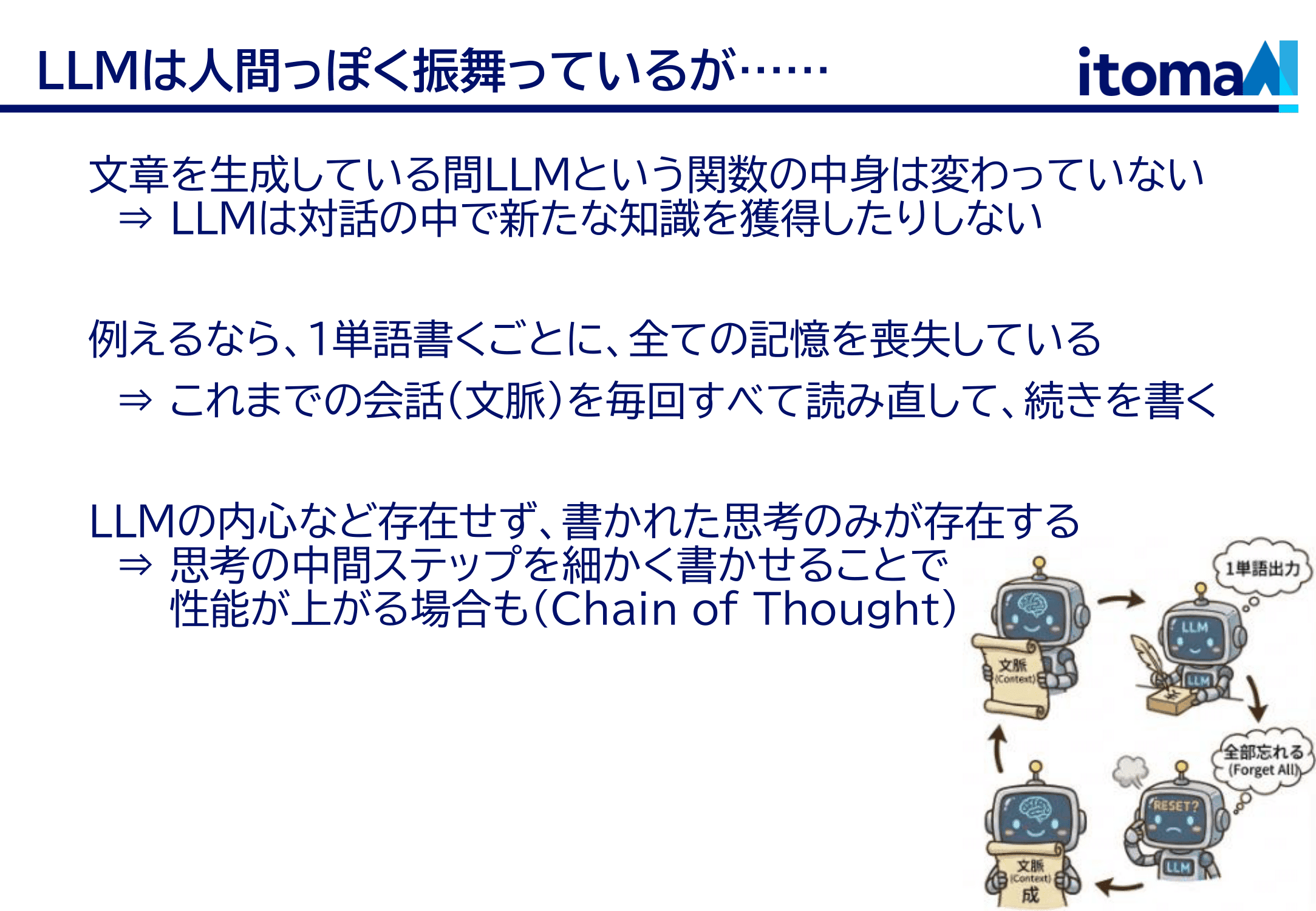
それだけの仕組みがなぜこれほど知的な振る舞いをするのか。その理由はおそらく Transformer という関数にあって、実はこれは推論するたびに内部で「学習っぽいこと」をしているらしいんですね。パラメータは変わっていないので本当の学習ではないし、人間がそうしろと言ったわけではないんですけど、適当にこういう形の関数を作ってエイヤと学習させたら、実は内部でパターン抽出(身長・体重の関係を直線でモデル化するみたいな)をやってたというわけです。もちろんこれは一単語出し終わったら忘れちゃうわけですけど。この仕組みは In-Context Learningという名前がついていて、熱心に研究されています。
さて、これほどの成果を上げている LLM というモデルですが、これはどこまで行けるんでしょうか?ちょっと前に面白い論文を読んだので共有するのですが、50% horizon という指標を提唱している人がいました。これは「人間がどのくらい長い時間をかけて完了するタスクをAIモデルが50%の成功率で完了できるか 」という指標ですね。人間が5分かけてできる仕事を AI が 50% の確率で達成できるようになったら、AI の 50% horizon は5分だということです。著者によれば2019年の LLM GPT-2 の 50% horizon は3秒でした。それが2025年の Claude 3.7 Sonnet は50分になっているそうです。だいたい7ヶ月で倍になっているということで、これを外挿してくと、1ヶ月のタスクを LLM が解けるようになるのは2030年ごろ、ということになります。
ただし、これはちょっと楽観的な推測だと私は思います。例えば、人間が1ヶ月の仕事をするとき、その間にちょっとずつ考えが深まっていって、物の見方が変わっていきますね?つまり人間は仕事中にも学習するわけです。でも今の LLM はそうではない。人間のように複雑な文脈の中で仕事をするためには、賢い関数を用意するだけではなく、仕事をしながらそのフィードバックを繰り入れていくような、つまりリアルタイムで学習し続けるような仕組みが必要です。その他いくつかのブレークスルーがいくつか必要で、多くのAI研究者は、本当に汎用的と言える AI が誕生するのは10年後くらいじゃないか、と言っています。私も妥当だと感じますが、ただ、未来何が起こるかはわかりません。案外3年後には完成しているかもしれないし、30年後にも GPT-5 から大きく先には進んでいない可能性だってあります。
AI とビジネス
ここまで AI の仕組みと発展の話をしてきました。残り時間は、AI と社会の関わり、AI とビジネスの話です。
AIが社会にもたらすもの
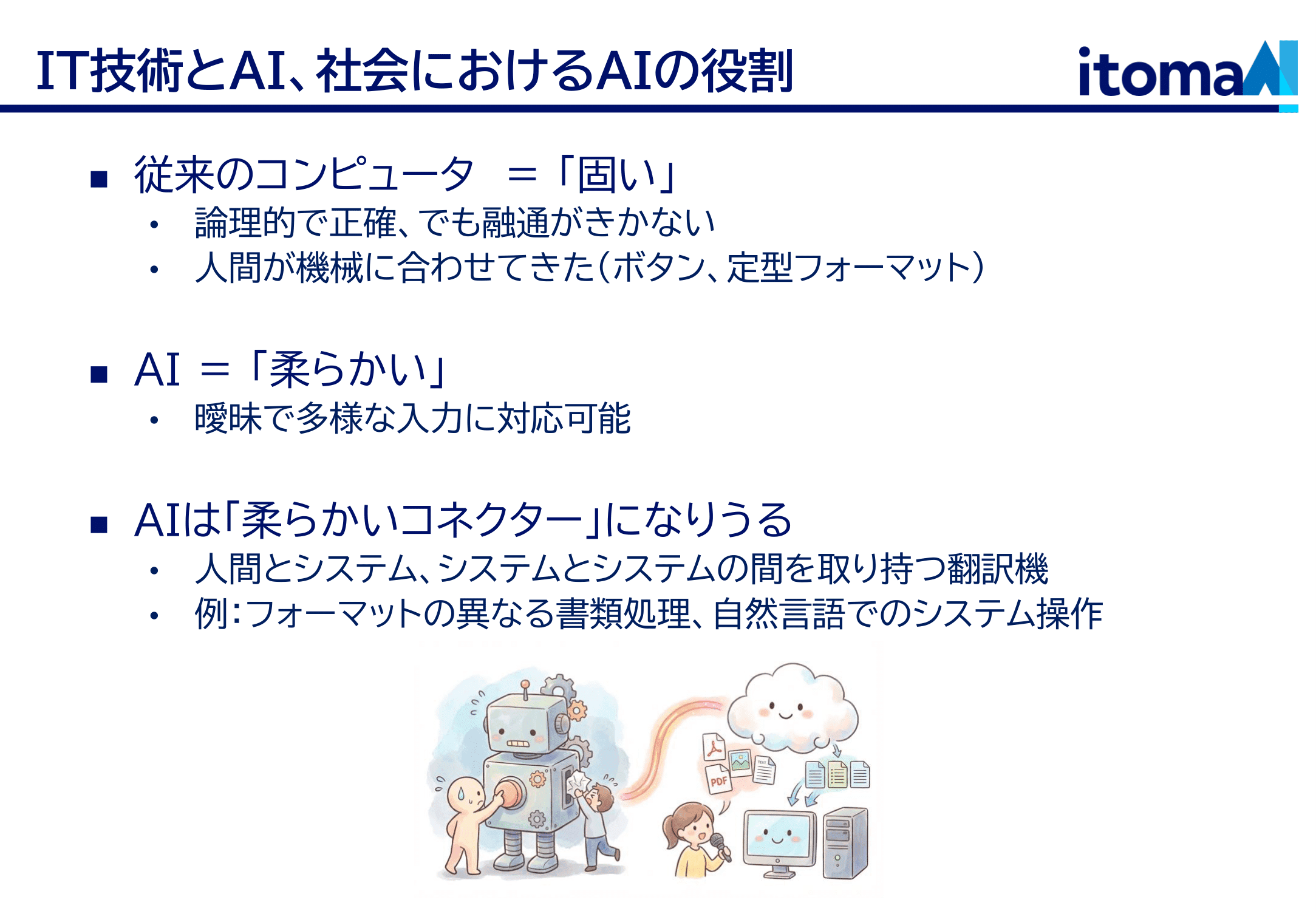
この講義シリーズのタイトルは「ITビジネス企画論」とお聞きしています。 AI というのも IT 技術に含まれますし、だからこそ私がここで機会を頂いているわけですが、AI にはこれまでの IT 技術とはすこし毛色が違うところがあります。それは IT が「固い」のに対して AI が「柔らかい」ということです。
IT 技術の根っこにあるのはコンピュータ、計算機です。計算機はプログラムで定義された情報処理を、圧倒的に速く、正確に行えます。だから業務を IT 化システム化してしまえば、物事はとてもスピーディかつ正確になります。例えば電車の改札とか、銀行の入出金とか。だから泥臭く頑張ってシステムを作るわけです。
その一方で計算機というのはもともと論理学の世界から出てきたものであり、厳密です。「プログラムは思った通りには動かない。書いた通りに動く」という格言があって、私はちょっと気に入ってますが、要するに柔軟性に欠けるのです。柔軟性というのは、言ってしまえば、入力の多様さ(ノイズ)に対応できるということです。例えば「新宿までの切符をください」という言葉での指示に反応して切符を発券するのは(AI以前の)コンピュータには難しかった。言い方が色々あるからです。だから人類は「ボタン」というインターフェースを発明しました。「新宿までの切符が出てくるボタン」があれば、コンピュータからすればそれが押されるか押されないかのどっちかなので、悩む余地がないのです。計算機の融通の効かなさに我々人間が合わせてきたわけですね。そして人間が自然に(あまり悩まずに)計算機に合わせられるように、様々なインターフェースが発明されてきたのです。
しかし AI の登場によってその状況が変わってきています。AI であれば、人間の言葉での指示を適切に理解しますし、それをプログラムに変換することが出来ます。つまり AI は、人間と計算機、あるいは計算機と別の計算機の「柔らかいコネクター」として機能するのです。難しい問題を解けるとか、悩みを聞いてくれるとか、たしかに個人として AI を使って感じる凄さはそのへんにありますが、しかし社会への影響という点を考えると、AI のインパクトはまず第一にこの「柔らかいコネクター」にあると思っています。言ってしまえばある種の翻訳です。そういう作業は世の中に多い。フォーマットの定まっていない書類を業務システムに入力するとか、仕様の異なるシステムの間を取り持つとか、電話注文に答えるとか。Transformer がもともと機械翻訳タスクで出てきた手法だと思うとすこし示唆的です。
AI に関わる仕事
さてもう少し話を狭めて、AI とビジネス、AI をどうお金に変えるかという話をしましょう。だいたい3つくらいのレイヤーがあると思っています。
1つ目は AI を作ることです。Google や OpenAI のように Gemini や ChatGPT といった大規模な AI を自前で実装し、訓練し、提供する。あるいは、より特化型の小さな AI を作る。私は長いことこの専門モデルを作るという仕事をしていました。というか、2020年くらいまでは、計算リソース・組織リソースの限界から、あるいは技術的限界から、みんな特定タスクに対して AI を訓練していたのです。また特化モデルを作るほうがいろいろな意味で良い場合もあります。しかし、世界的な潮流としては、大規模化へと向かっています。莫大な計算資源と学習データを放り込めばいろんなタスクが勝手に解けるようになってしまう(「創発」とか大仰な名前で呼んだりしますね)ことが分かってきましたし、ひとたび汎用人工知能(AGI)が完成すればその利益は計り知れないわけで、資本のある大企業はこぞって開発に取り組んでいます。すごいお金がかかります(モデルひとつを学習するのに数百億円くらいかかります)。日本企業にももっと頑張って欲しいものです。
2つ目は、大企業が提供する AI を加工して、つまり適当なガワで包んで売ることです。私達のようなスタートアップや多くの IT 企業がやっていることです。そのやり方にも、いくつか方向性があるように見えます。
ひとつは AI の自律性を売りにするというもの。例えば AI エンジニア Devin なんていうプロダクトがあります。これは、ソフトウェア開発の一部ないし全工程を AI に任せてしまおうというものです。ソフトウェア開発の分野は、もともと AI の導入が積極的で、Github copilot とか Cursor とか、AI を前提とした開発環境が多く提供されています。ソフトウェアというのも一種の文章であって LLM との相性が良いのです。学習データが大量に存在したというのもあります。こうしたプロダクトを使うと、自分ではほとんどコードを書くことなく短期間で勝手にアプリだのウェブサイトだのが作れてしまいます。
もう一つは、先ほどお話した「柔らかいコネクター」として AI を使うもの。AI は柔軟ですが、それだけだと柔軟すぎる場合も多い。使ったことのある人は解ると思いますが、同じ話しかけ方をしても、返ってくる言葉は違ってくる。でも世の中の業務フローはある程度決まっています。つまり、要所要所では柔らかく対応してほしいけど、全体としては一定のルーチンを守ってほしい、という場合がしばしばあるわけです。そのような場合には、業務ドメインの内容や特性をよく理解した上で、ここぞというところに AI を導入するほうが良かったりします。地味ではありますが、特定の業界に深く入り込めば、手堅いビジネスになります。われわれが主にやっているのはそういう仕事です。
3つ目は、AI をあくまで裏方として使うというもの。要するに、普通にユーザーとして AI を使うというやり方ですね。例えばわれわれは AI 導入を支援したり、プロダクト開発をしたりしていますが、その作業においては AI をかなり使っています。限界もままありますが、うまく使えば、人手でやるよりも遥かに効率的です。AI を梃子として使うことで大きな利益を上げている会社さんは多くあります。ただし、AI が普及するにしたがってそれが当然のものと考えられるようになるため、AI 導入がしやすい業種は単価は低下していくだろうとも思われます。
AIは人の仕事を奪うのか? → 長期的にはYES.でも順序はある

長期的には、AI は人間を完全に代替するだけの能力を持つだろうと思います。人間が物理的な機械である以上、それを再現できない道理はないからです。でもそれは10年かそれ以上はかかるでしょうし、原理的にできるからといって、それが適切であるかもわかりません。
深層学習が流行りだした当初から、「専門技能の非属人化」は AI に期待されていたことでした。人の目でやっていた半導体の検査を自動化するとか、高齢の技術者がいなくなる前に技能を AI に継承したいとか、そういう要望やプロジェクトはたくさん見てきましたし、関わってきました。しかし振り返ってみると、これはうまくいった例がそれほどないように思います。専門家の仕事というのは、単純な作業ではなく、高度な文脈の上に成り立っているからです。目に見える単一の技能を機械化出来たところで、それだけでは意味がないということはままあります。また専門性が高いということは訓練データが限られる(やっている人が少ない)ということでもあります。AI がやっているのは基本的には目に見えるデータの模倣ですから、限界がある。逆に AI が得意なのは「誰でもできるけど面倒くさい仕事」の代替です。メールの返信とか議事録作成、簡単なコーディング、このような汎用的で大量にある仕事がまず AI に置き換わっていきます。
結局のところ「その仕事は関数(入力と出力の関係)として切り出しやすいか?」という観点が重要だと思います。高度で専門的な技能であっても、入出力の関係が明確なものは AI に置き換えられやすい。この観点を持っておけば、自分で AI プロダクトを作ることも出来ますし、逆に AI に侵食されにくい職業を選ぶこともできるかもしれません。また AI 関係なしに、人に仕事を頼む上でも重要な観点です。経営をはじめて強く感じることですが。
最後に
今日の話は、まとめると以下の3つです。
- AI は関数である。ただし学習する関数である。
- AI の特徴はその柔らかさ
- タスク(=関数)としての切り出しやすさ = AI 化のしやすさ
AI の登場によってこれから社会は激変していくでしょう。摩擦や混乱も多く生じると思います。でも、私達が人類の歴史において、極めて重要で興味深い転換点に生きているというのも事実です。荒波をうまく乗りこなしながら、人生楽しんでいきましょう。